The Answer to the Common Question: What is Quine or Streaming Graph?
“Quine is a real-time streaming graph that fits perfectly between two Kafka instances.”
This is the most common answer I give whenever a data engineer asks “What is Quine?” As an answer, it works remarkably well. The reason it works is simple: everyone knows what Kafka does, even if they don’t run it themselves in production (which is rare).
It is also a heck of a lot pithier than:
“Quine is an open source stream processing application with a graph data model designed to ingest high volumes of event data from sources like Kafka or Kinesis and process them in real time using Cypher or Gremlin. The results of those queries can then be used to update the graph itself, can be stored in another database or data warehouse, or can be output back into the Kafka or Kinesis-based data pipeline. thatDot Streaming Graph is the commercial distributed high scale version.”
While accurate, this isn’t exactly a conversation starter like the shorter description.
Inline Graph Analytics
One of the first “a-ha’s” when we talk to data engineers operating real-time data pipelines is that while Quine shares much in common with graph databases (data is represented as nodes and edges, nodes have properties, and you can query it using the two most common graph query languages), it is radically different in one specific way: it runs inline with your stream, becoming another part of the data pipeline.
Unlike graph databases, which are static stores accumulating data and are therefore essentially an off-ramp from the data stream, Quine doesn’t divert the flow of data through the system.
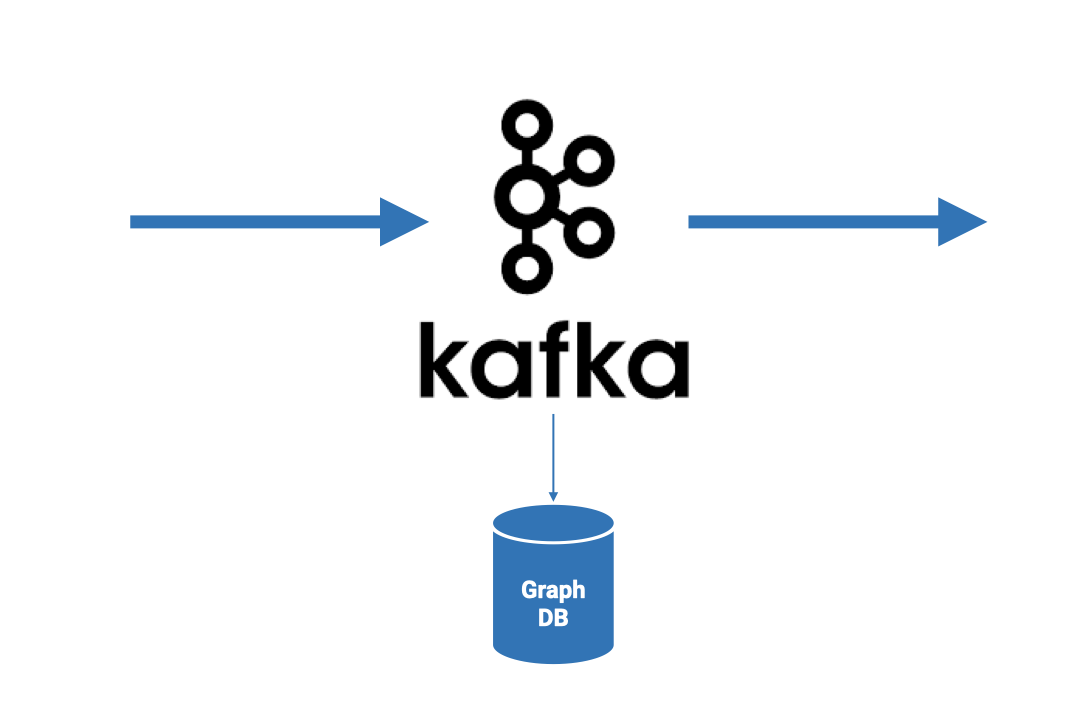
Graph databases cannot process data inline in real time.
This is not meant to be a slight on graph databases. They just weren’t built from the ground up to exist inline with Kafka-driven data streams.
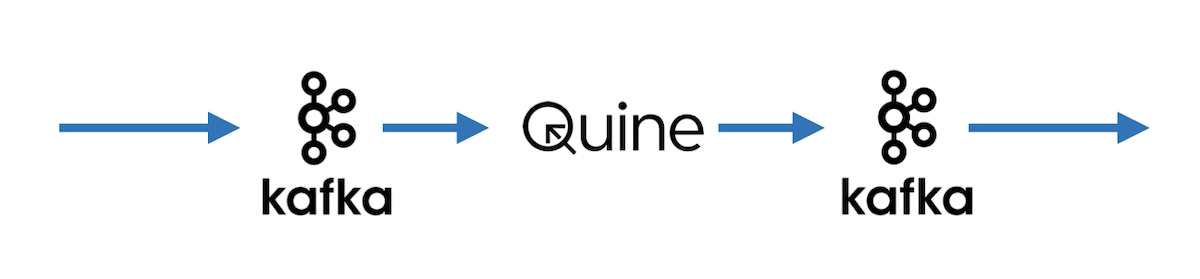
Quine runs inline with the data flow to process data into a real-time graph .
Ingesting Kafka data to build a Real-time Streaming Graph
As the diagram above implies, Quine ingests data from Kafka and turns it into a dynamic streaming graph. In the fifth installment of his Ingesting Data into Quine blog series, Michael Aglietti covers the how’s and why’s in detail so I won’t delve too much deeper here.
I will make a few points:
- Streaming Graph scales with Kafka – Quine is designed to process streaming data and turn it into a graph without slowing down the flow of data through the system. A single node of Quine can ingest and process thousands of events per second hosted on a commodity server. A thatDot Streaming Graph cluster can process millions of events per second with tens of thousands of simultaneous queries.
- Quine takes advantage of Kafka’s ability to regulate the stream – as anyone who has operated a production system knows, things don’t always go smoothly. Perhaps a host in a Streaming Graph cluster fails and throughput slows as a hot spare comes online. In that case, Streaming Graph counts on Kafka’s ability to handle back pressure. But that’s not all. Streaming Graph itself is also back-pressured. If Quine or Streaming Graph is busy with a resource-intensive task downstream, or possibly waiting for the durable storage to finish processing, it will back pressure the ingest stream so that it does not overwhelm other components.
Inline means Not Just Ingest but Output
If Quine were just a highly write-optimized graph data processor, it would be pretty remarkable. But inline means keeping the data flowing through the pipeline. It means Quine is not just a sink in Kafka terms but a high-velocity source. And this is where Quine is truly unique.
If ingest streams represent the sink side of Quine, standing queries turn Quine into a source.
The way standing queries work is that they persist at all times on all nodes in the graph, accumulating partial matches as data flows through and triggering an action when a complete match is made. Think of them as a net you stretch across the data stream that is designed to catch only specific data patterns.
Once a match is made, the standing query triggers an action which can include executing an arbitrary piece of code, updating the graph itself, writing the results out to a database, or publishing data right back out to a Kafka topic.
And it can do this all with sub-millisecond latency.
It’s at this point in a call that the record scratch sound effect interrupts the conversation and one of the engineers on the call is like, “Hold up….I don’t believe you.” (If “Quine lives between two Kafka streams” is what we repeat most often on calls, “I don’t believe you” is what engineers we are talking to most often say.)
Standing queries turn the whole idea of querying a database on its head. They are far more equivalent to the continuous queries of an event stream processor. They work because Quine is built on an asynchronous actor model. That is, every node in the graph also has an actor associated with it capable of performing discrete compute tasks and sending messages to other nodes. The Quine technical white paper digs into this all in depth if you are interested. What is important about standing queries is they allow Quine and Streaming Graph to not just ingest high volumes of data but process the data and then send it out to continue its journey through the data pipeline. No off-ramps. No slow downs.
When real-time really does mean real-time
By way of conclusion, let’s revisit the statement that kicked off this post: “Quine is a real-time streaming graph that lives between two Kafka instances.”
Graph analysis is incredibly powerful, especially when it comes to maximizing the value of categorical data. Graphs allow you to express relationships between objects in a direct and natural way that is both human readable and performant. Use cases like XDR, financial fraud detection, authentication attacks, insider trading prevention, or network observability and root cause analysis, would all benefit tremendously if they could apply a graph model to their data.
So why don’t they? The single biggest reason – and another thing we hear on calls all the time – is that graph databases can’t process the data fast enough. People end up batch processing data, which is the opposite of real time.
Quine is real-time graph processing that sits inline with your Kafka-based data pipeline and detects complex patterns the instant they emerge. Drop Quine in between two Kafka instances and you will discover a whole new dimension to your data.
And if you don’t believe me, that’s okay. We’re used to it.
Next Steps and Further Reading
thatDot Streaming Graph is the commercial, distributed cluster scale version. Try it out in the Free Trial.
Quine is open source if you want to try it for yourself. Download a precompiled version or build it yourself from the codebase Quine Github.
Or drop into the Quine Discord Community. We’re always happy to discuss Quine or answer questions.
And if you have a question, suggestion, or improvement, Contact Us.
And if you’re interested in learning more about building a streaming graph from various ingest sources., check out previous installments in this blog series:





