Is it better to fix a problem now or later?
The typical answer when someone describes the difference between batch processing and stream processing is that batch data is collected, stored for a period of time, and processed and put to use at regular intervals (e.g. payroll, bank statements) while streaming data is processed and put to use as close to the instant it is generated (think of alerts from sensor data).
While accurate, this answer fails to capture why the difference is important and why companies are moving decisively toward stream processing architectures. We experience the world as a constant stream of events. We make decisions by comparing this stream of information to our experiences and memories.
We perceive and react to threats or recognize and seize opportunities. And often reacting in a timely fashion is rewarding – we avoid the snake bite or grab the best seat at the movie theater. Stream processing more closely reflects this very human mode of experience.
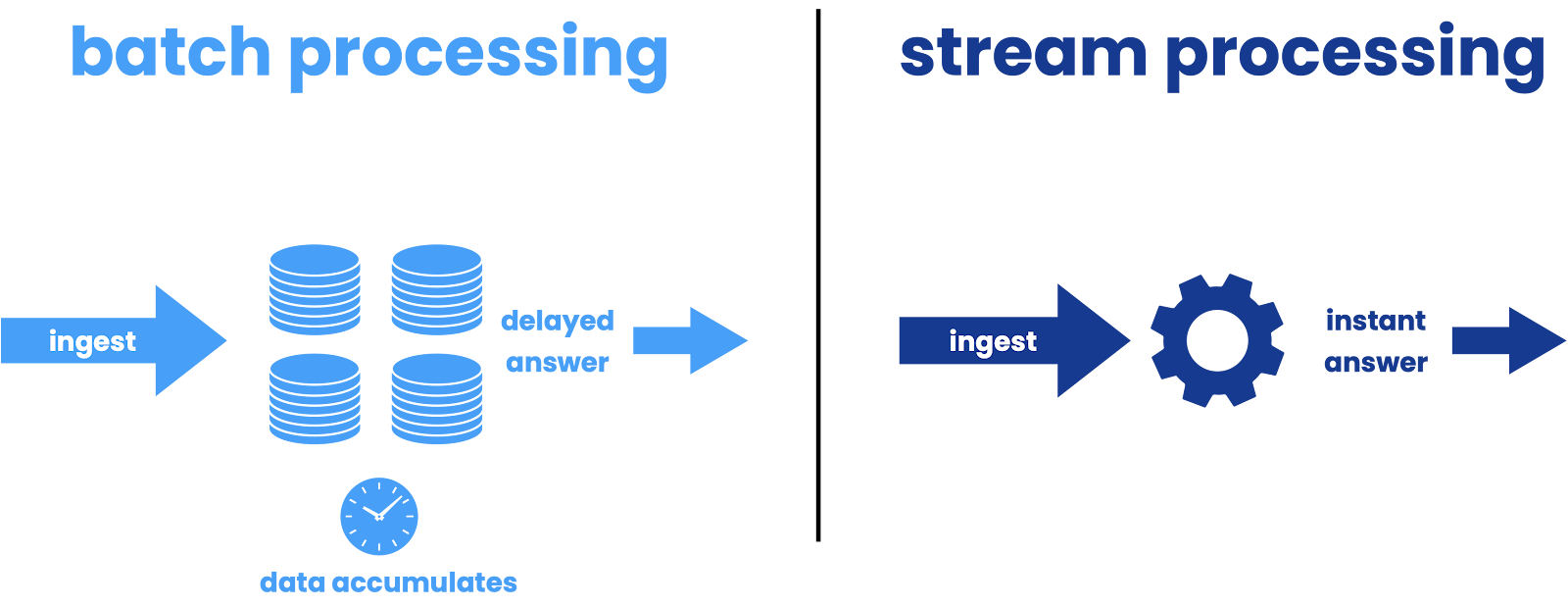
Enterprises ingest as many streams of information as they can handle, look for patterns in the data that represent threats or opportunities as it flows past, and when said patterns emerge, they act. The cost of not acting could be a data breach or a lost revenue opportunity. Batch processing still works well when you need to process huge amounts of data and the results can be delivered at regular intervals. But if recent trends hold, more of these jobs will move to streaming because companies can’t accept the hidden cost of batch any longer and remain competitive.
Counting the Cost of Not Acting
A great example is insider trading. The cost of detecting someone who is about to execute an insider trade is now much less than the cost of trying to unwind that trade later when batch processing picks it up. Even if the batch process runs every five minutes, that just means you’ll find them sooner, not stop them.
Ultimately stream vs. batch will show up in the balance sheet and the stock price. The one potential argument against streaming is that it might not handle the amount of data as cost effectively as batch handles. However, with the advent of systems like Kafka, Flink, and their cloud analogues, such cases are getting rare.
Quine Stream Graph for ETL Pipelines
We build Quine to not just detect emerging patterns of interest in high volumes of data but to act on the results with sub-millisecond latency. Practically speaking, this means finding evidence of a password spray attack or streaming CDN service interruptions when they are technical issues and before they become business issues.
Quine consumes event data from one or more streams originating in Kafka, Kinesis, or data lakes, uses a graph data structure to materialize the often complex relationships between events that evidence important system or user behavior. Quine uses standing queries to trigger actions like sending alerts or updating machine learning models the instant such patterns become apparent.
Far from acting as a passive filter, Quine actually drives the workflow. And Quine scales to meet the needs of modern enterprises, as this test demonstrating Quine’s ability to process and alert on one million events/second demonstrates.
When to Use Quine
Batch processing is great for jobs where response time doesn’t matter. And batch processing tools have been around for a long time so you have your choice. But for jobs where the cost of not knowing and therefore not acting are unacceptable, Quine is idea. For use cases like financial fraud detection,video observability, and manufacturing process management using a digital twin, Quine streaming graph is really the only choice.
Getting Started
If you want to try Quine using your own data, here are some resources to help:
- Download Quine – JAR file | Docker Image | Github
- Start learning about Quine now by visiting the Quine open source project.
- Check out the Ingest Data into Quine blog series covering everything from ingest from Kafka to ingesting .CSV data
- CDN Cache Efficiency Recipe – this recipe provides more ingest pattern examples
And if you require 24 x7 support or have high-volume use case and would like to try the Quine Enterprise, please contact us. You can also read more about Quine Enterprise here. Special thanks for the image used in the image to Amritanshu Sikdar on Unsplash.





