The High Cost of Storing Low Value Data
The high cost of SIEM has given rise to countless articles and dozens of companies promoting strategies or products to reduce monthly bills, with some claiming 50-90% reductions.While the 50-90% number seems a little overblown and sure to be met with skepticism — enterprises tend to take a “better to store it and pay the price than regret we didn’t later” approach, especially when the data may have compliance implications1 — the appeal is easy to understand.
I took a look at the current methods for reducing SIEM costs and compared them to what graph ETL using Quine can accomplish all while considering impact on data fidelity.
The State of Stream Pre-Processing: Random, Destructive, and Only Somewhat Effective
Legacy event log pre-processing offerings typically employ one or more of six basic strategies to reduce the amount of data stored in the SIEM:
- Sample data
- Filter out fields
- Filter out events
- De-duplicate
- Aggregate/roll-up
- Re-route some data to cheaper alternatives for cold storage (e.g,. Logstash or Amazon S3)
These solutions also usually include the ability to set rules that refine system behavior by data source or event type – for instance, sampling one in five events from a log of failed authentication attempts but one in twenty events from an Apache access log.
It is important to note that stream pre-processing can only be applied to each stream and each record individually. Since many modern event processing use cases — not just SIEM but those for machine learning and e-commerce — depend on combining multiple data sources to model complex events, the single-stream approach means storing duplicate data from each stream required to connect them later (in SQL terms, these data are the keys used to join the various data sets once they are stored).
We were paying for 600 [GB] to 700 GB per day with Splunk, which meant we were lousy co-workers to our IT group, because we had to tell them, ‘Send us this field, not that field,’ and limit the data ingestion severely,” said John Gerber, principal cybersecurity analyst at Reston, Va., systems integrator SAIC. — from Elastic SIEM woos enterprises with cost savings
As the quote above makes clear, some approaches also require lots of operational intervention, meaning delays for analysts and data scientists and an overall increase in cost of ownership.
The more important limitation is that these approaches cannot determine the value of the data they discard. They either throw data away or, in the case of aggregation, reduce fidelity. All data is considered to have the same value.
Quine’s approach is different: it turns high volumes of low-value data into low volumes of high-value data.
Instead of storing data in Splunk or a similar system and then determining value, Quine can evaluate data as it arrives and make choices to store or discard based on the problem you are trying to solve.
Quine Ingest Queries: Semantic ETL for High Value Data
At the heart of how Quine processes data are two query types: ingest and standing queries (more on the latter below).2
Quine uses ingest queries to consume event data and construct your streaming graph database. Ingest queries perform real-time ETL on incoming streams, combining multiple data sources (for example from multiple Kafka topics, Kinesis streams, data from databases, live feeds via APIs) into a single streaming graph, eliminating the need to keep duplicate data around for joins.
Using Quine’s ingest ETL, you can join all the data, eliminating cross-data stream duplicates. That accounts for some incremental data reduction over existing methods, which along with the other five strategies (all of which Quine supports) means Quine offers superior savings on your SIEM costs. But more than just deduplicating data, joining streams lets you draw conclusions early about what makes some data more valuable than other data.
Quine’s real power, however, is its ability to apply a semantic filter to your data to find patterns made up of multiple events. And it does so as data streams in.
Save Only the Patterns That Matter
Ingest queries make it easy to organize the high value, often complex, patterns in data into graph structures. These patterns are characterized by the relationships between multiple events. In a practical sense, you are shaping the data into a form that anticipates the analysis you will perform downstream in your SIEM. Quine can join, interpret, and trim away any data not relevant to the answers.
What you end up creating in your graph-ETL are subgraphs, or patterns of two or more nodes and connecting edges.
Here are a few real world examples from the Quine community:
- Find and store all instances where there have been attempts (both successful and failed) to log into the accounts of members of the executive team from multiple IP addresses

A subgraph for monitoring authentication fraud attempts.
- Find and store all instances where multiple processes in different office locations are sending message to the same IP address

A subgraph for monitoring processes and the IP addreses to which they write.
In both of these examples, the test for what you keep and what you discard is based on what might possibly be important, on what matters to your business.
What if data takes time to become interesting?
One challenge processing streaming data – especially when event data arrives from many networked sources – is that it can arrive late or out of order, obscuring what would otherwise be an interesting pattern. Consider the examples above.
What if the login attempts in example one were spread out over days or even weeks?
What if log events from several locations in example two (above) were delayed for several hours or started at different times? Quine handles this late arriving data (as well as out of order data) using standing queries.
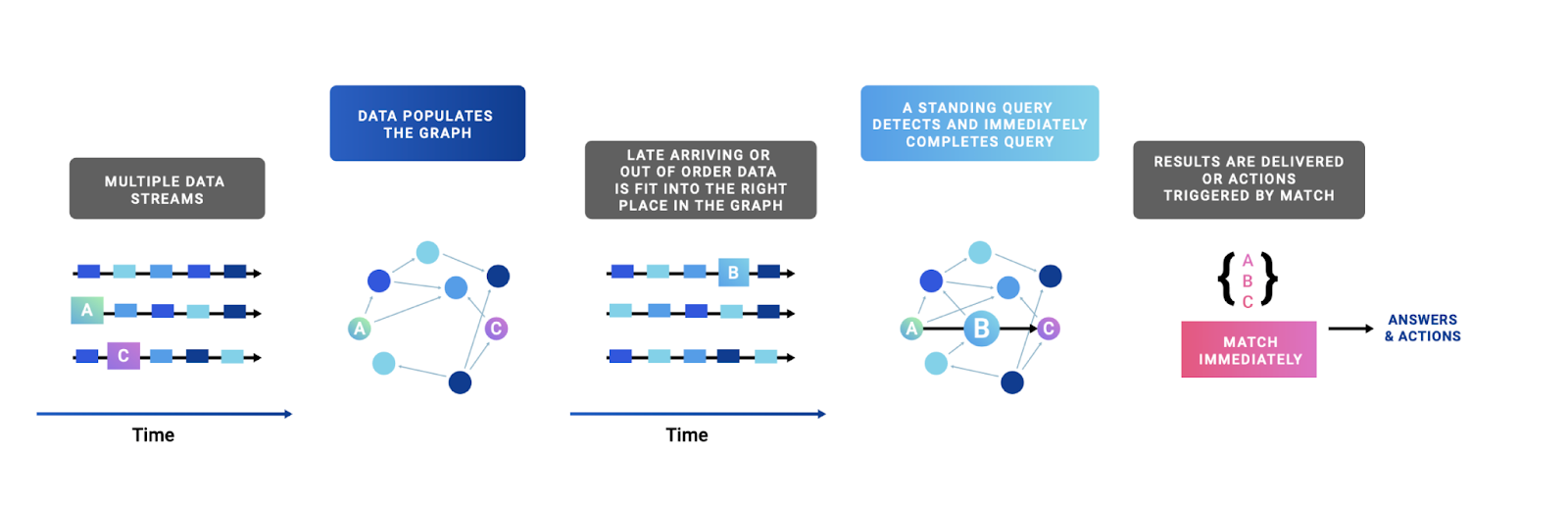
Standing queries persist in the graph, storing partial matches and triggering actions when a full match occurs.
Standing queries live inside the graph and automatically propagate the incremental results computed from both historical data and incoming streaming data. Once matches are found, standing queries trigger actions using those results (e.g., execute code, transform other data in the graph, publish data to another system like Apache Kafka or Kinesis).
The implication for SIEM storage reduction is that Quine can temporarily retain possibly interesting incomplete patterns until a match occurs. It is neither discarded nor taking up costly space in your SIEM. Then, at the instant the match occurs, it is sent along to the SIEM system for regular processing. If a match doesn’t occur within a useful period, the data can be discarded automatically.
Want to go further? Consider bypassing your SIEM altogether and sending alerts and data directly to your SOC or NOC’s dashboards, analysts, or data science team as it arrives and matches occur. But that’s for the next blog post. Until then, try out Quine’s graph ETL on your own log data. It is open source and easy to get started with.
Who knows, it might just save you a few million dollars.
Help Getting Started
If you want to try it on your own logs, here are some resources to help:
- Download Quine – JAR file | Docker Image | Github
- Check out the Ingest Data into Quine blog series covering everything from ingest from Kafka to ingesting .CSV data
- Apache Log Recipe – this recipe provides more ingest pattern examples
- Join Quine Community Slack and get help from thatDot engineers and community members.
——
1 Set aside that there are better, cheaper alternatives for this specific use case (using an expensive SIEM provider this is sort of like renting a penthouse apartment for all your junk instead of a storage locker) and the fact remains: companies aren’t going to get rid of a certain amount of their data, no matter what.
2 If you are interested in a deeper technical understanding of Quine’s architecture, try our white paper.





