It is almost inevitable when talking to data engineers or scientists about Quine streaming graph that they start ticking off all the graph databases they’ve already tried and how vastly different each was to operate. That’s not surprising. The tidy category name of graph database obscures what is in fact a pretty diverse set of database technologies. From purpose-built graph databases (Neo4J and TigerGraph) to triple stores (AWS Neptune), and from distributed graphs tightly coupled to column stores (Titan) to multi-model document stores with graph wrappers (ArrangoDB and OrientDB), you’ll find widely divergent underlying data structures, indexing and storage architectures, performance profiles, and target use cases.
They have two traits in common that always come up in these calls, though: they all behave like classic databases in that you must proactively query them to see if data is available and they’ve proven unable to scale beyond what are today relatively modest workloads, especially increasingly common event stream processing workloads. Those two traits are in fact profoundly interconnected. Querying a database until you get the answer you need is such a deeply ingrained pattern when it comes to detecting patterns in data that we don’t even question it. It is also grossly inefficient. Compute resources are spent polling for data that is either not in the database or has been in the database for some amount of time.
The only way to know if the data is available is to issue the query. Applying this model to event streams of even moderate volume (e.g. 1,000 events/sec) only compounds the problem, rendering graph databases incapable of delivering results in anything close to a reasonable timeframe. [link to benchmarking whitepaper] So when we describe how Quine can scale up to thousands of events/second per node, handle out of order and late arriving data, and doesn’t rely on time windows, people actually tell us they don’t believe us.
That’s impossible, they say. How? Our answer? Stop querying your data. It sounds absurd or deliberately provocative, but this is exactly the design choice Quine makes. Quine is a streaming graph. It combines characteristics of complex event processing software (consuming high volume event streams from Kafka and Kinesis) with some of the defining aspects of graph databases.
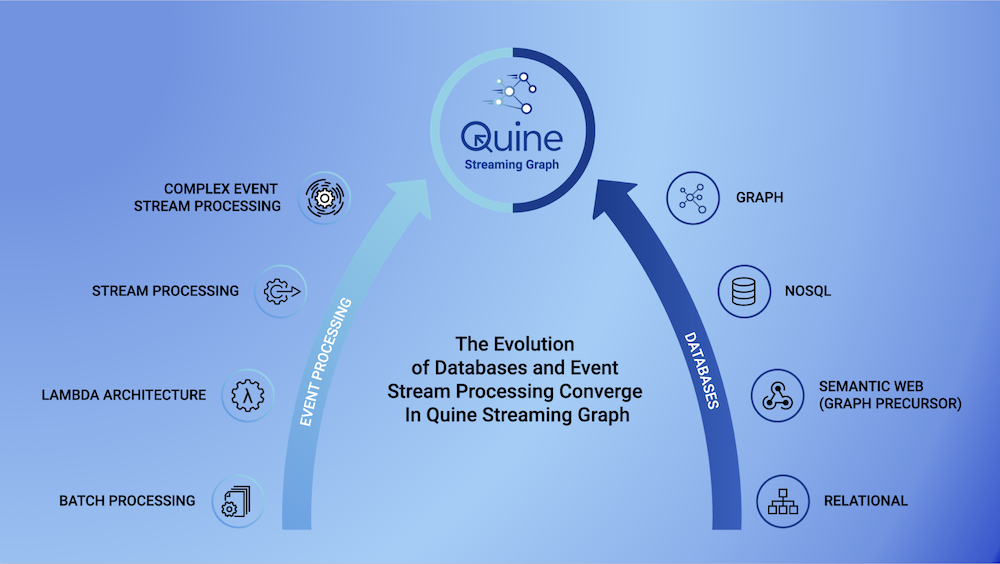
The evolution of Quine streaming graph.
Quine supports the Cypher and Gremlin query syntax, its data structure is defined by nodes, edges, and properties of nodes, and it performs best when you structure your graph for the questions you need answered. Quine’s approach to finding complex patterns and relationships in event data, and the scale at which Quine operates, differs fundamentally. Quine doesn’t query the database.
When is a query not a query? When it is a Quine Standing Query.
The standing query is what makes Quine different. And after spending several hundred words telling you not to query your data if you want to scale, I must admit the name might be misleading. But 1) naming is hard and 2) let’s focus on the standing part for now. A standing query is like a filter on streams of event data. You issue it once, it propagates into the graph and then…you wait.
As events stream in, standing queries keep track of incremental changes in the graph state. At the instant a match is made, the standing query springs into action, triggering an arbitrary operation you’ve specified – updating node properties, adding edges, writing out to a Kafka topic or a database.
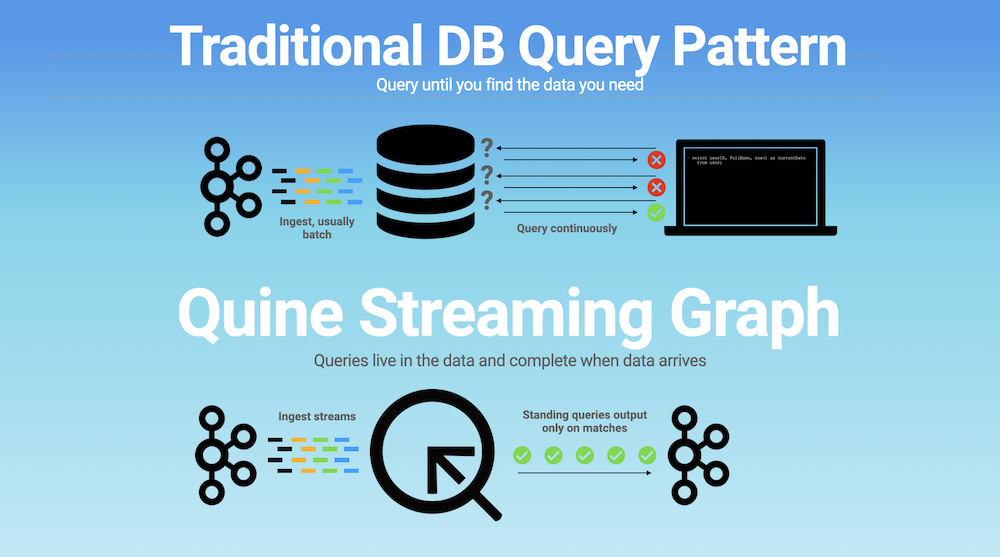
Traditional DB query patterns vs. standing queries in Quine streaming graph
How is this possible without expending tremendous compute resources? The key innovation that makes standing queries possible – and therefore allows Quine to scale to millions of events per second — is that Quine combines a graph data model with an asynchronous actor-based compute model built on the same graph. In Quine, every node both stores data and can instantiate an actor as needed to send and receive messages and perform arbitrary computation on these messages.
Actors are similar to threads in that they are computationally efficient, can be loaded on-demand and are reclaimed when no longer needed. Going back up a level, this design makes possible the incremental compute necessary for a standing query. As events are ingested, actors on nodes responsible for a standing query detect incremental changes to the graph state that matter to them and pass messages up a tree-like hierarchy of nodes responsible for coordinating the standing query.
Again, all this is done with lightweight actors and no compute is expended except when incremental matches are made. Unlike with graph databases [PDF; see section 6.3 Complex Queries], the patterns standing queries filter for can be quite complex without increasing query latency. In fact, the notion of query latency doesn’t really exist. A match is made when the data necessary for the match is present. No resources are expended until that happens.
Then, and only then, is an action triggered. Standing queries aren’t the only reason Quine processes high-volume event data so effectively. Its use of semantic caching – also a byproduct of a graph-based data and compute model – and division of read and write concerns between an in-memory graph structure and write-optimized persistors both contribute to its ability to scale. But it is the decision to not actively query the data that unlocks the performance at scale necessary for event-driven applications.
Graph databases remain a great choice for many uses. And the graph query syntax they mainstreamed is highly effective for finding deeper, more valuable relationships between events. But as event-driven data grows in both volume and importance, graph needs to evolve away from the old database patterns.
Learn more or try Quine Streaming Graph
If you are interested in learning more about Quine’s architecture and design choices, or if you want to try Quine for yourself, visit Quine.io for docs and downloads.





