Streaming Graph Combines Graph DBs with Stream Event Processing
Quine’s graph-based streaming event architecture simplified my processing codebase. I tried pre-aggregation of rollup data using a Kafka streams application and found that other solutions like Kafka Streams KTables were not well suited, or a natural fit, for my data set. So, then my team fell back on relational database (RDBMS) path table patterns to represent the hierarchical data. With the RDBMS we recomputed the rollups using complex recursive function queries through the path-table structure, each time our UI needed to display that data. Using Quine, I replaced the complex queries with succinct Cypher queries for the stream computed rollup value that updates at each underlying event change.
The Cypher query language used in Quine encourages treating relationships as a primary quality of your data. It provides a rich set of features for constraining queries across multi-step relationships. The depth constraints on the relationship allowed me to replace those recursive SQL functions with a n-depth relationship expression. As I will show later, I was able to match all tiers of my hierarchical data with a single expression.
In my use case, I have a hierarchical graph of meta-data that groups sets of pass/fail Requirements. Event data carrying pass/fail results relate directly to leaf nodes in a hierarchical graph. Complete sets of events are produced for multiple subjects, and we need to be able to provide the percent pass vs fail for each subject at every level of the grouping hierarchy.
Inserting Quine into my Kafka streaming pipeline is done by simply consuming from topics that are already inputs in Kafka. When deployed, Quine is configured to ingest data from my existing results topic, and my grouping data topic. The new outputs from Quine are subscribed to by the streams recording service and written to the database.
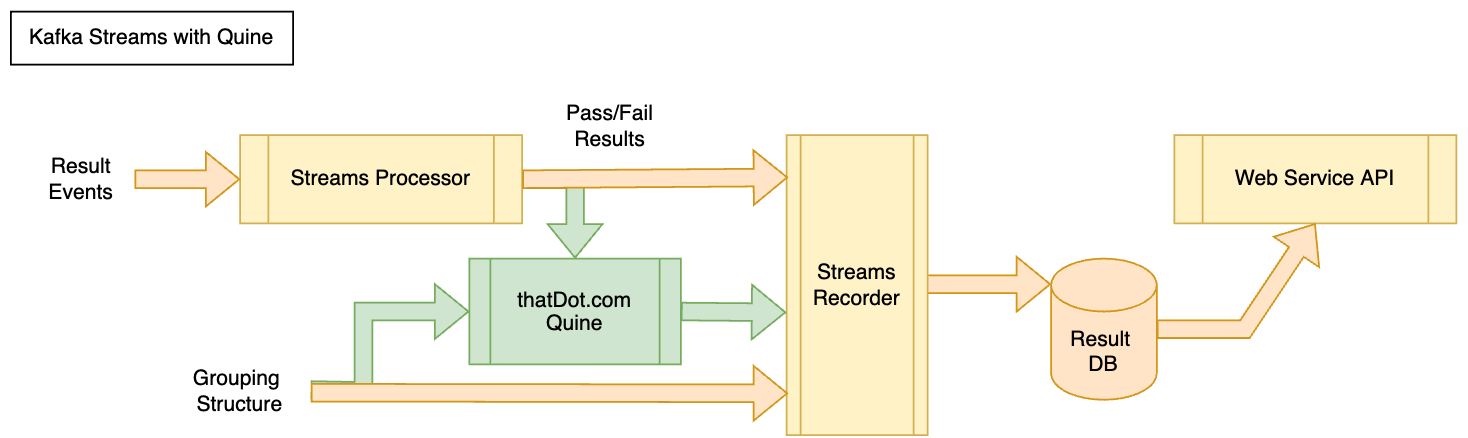
Ingesting the Data
In my system, when the grouped Requirement data is updated, it is streamed out over a Kafka topic. Systems being evaluated for satisfaction of these requirements produce Result events that are dis-embodied from the grouping context. They also flow in on a Kafka topic.
I started by populating the Quine graph with my hierarchical data. From my perspective, the easiest approach to this is to first pre-process the groups and leaf nodes into content suited for streaming input. So, a JSON document that has nested data structures can be flattened into expressions of nodes and their relationships. This upfront transformation can easily be performed by something like a Kafka-Streams application.
I transform something like this document:
{
“groups”: [
{
“name”: “group-1”,
“groups”: [
{
“name”: “group-1-1”,
“items”: [
{ “name”: “requirement-1.1-a”, … },
{ “name”: “requirement-1.1-b”, … }
]
}, …
Into this list of events that express the parent group relationship:
{ “name”: “requirement-1.1-a”, “group”: “group-1-1”, “type”: “requirement”, … }
{ “name”: “requirement-1.1-b”, “group”: “group-1-1”, “type”: “requirement”, … }
{ “name”: “group-1.1”, “group”: “group-1”, “type”: “group”, … }
{ “name”: “group-1”, “group”: “root”, “type”: “group”, … }
When the data flows into Quine, it is detected by two (2) ingest queries. I used a different query for each value of type in my input JSON. The query is expressed as JSON data that you POST to the /api/v1/ingest/<name> REST endpoint. You can set <name> to a unique value by which the ingest query can be identified. For example, my query path was: /api/v1/ingest/test_groups.
{
…,
“format”: {
“query”: “
WITH * WHERE $that.type = ‘group’
MATCH (g)
WHERE id(g) = idFrom(‘group’, $that.name)
OPTIONAL MATCH (parent) WHERE id(parent) = idFrom(‘group’, $that.group)
CREATE (g)-[:has_parent]->(parent)
SET g = $that, g:Group
“,
“type”: “CypherJson”
}
}
Note: While in production, I ingest my data from the Kafka streams. However, for experimentation I used the FileIngest type of ingest query. This allowed rapid exploration of Quine without having to force events to be sent through Kafka. In that case, you would add fields like: type: FileIngest, path: /json/file/to/load.json
This ingest query matches all records flowing in where the json record referenced by $that has a field named type with a value of group. We will refer to it as node variable g. The WHERE clause says the id of the node g must be equal to the result of the idFrom function. The idFrom function creates a unique, reproducible ID from the sequence of values given. In this case we will include our node type, and record name. You do not have to worry about concerns such as if the node already exists. If it does, g will reference that node. If it does not, g will materialize a node for the computed id. The SET part later assigns all the fields in the incoming record as properties of the node, updating g if it previously existed.
This ingest-query also creates a relationship between node g and the parent node identified by the group field in my incoming records. The OPTIONAL MATCH creates a secondary node query, exactly like the one for node g but this time the values passed into ‘idFrom’ represent the parent node. Then we declare a relationship using CREATE that says node g relates to parent node, and we name that relationship has_parent.
Quine adds the idFrom function to the Cypher query language, along with the implicit materialization of nodes in match statements to facilitate building the graph from streaming sources without requiring your application to be concerned with the order of data insertion. If we know the expected identifier for the node that we are creating a relationship to, then it will materialize. It just will not have the attributes until a specific record adds them.
I repeated this pattern to also ingest the requirement records. At this point my hierarchical data is represented in the Quine graph. Next, I have event records that have relationships to a Subject and a Requirement. This one is a little more complicated:
{
…,
“format”: {
“query”: “
MATCH (result), (requirement), (subject)
WHERE id(result) = idFrom(‘result’, $that.subjectId, $that.requirementName)
AND id(subject) = idFrom(‘subject’, $that.subjectId)
AND id(requirement) = idFrom(‘requirement’, $that.requirementName)
CREATE (subject)-[:results]->(result)-[:requirements]->(requirement)
SET result = {status: $that.status, timestamp: $that.timestamp}, result:Result, subject = {subjectId: $that.subjectId}, subject:Subject
“,
“type”: “CypherJson”
}
}
The above ingest query matches three different nodes as the data flows in, based on identifying data in the event record. It then assigns the event data to the subject and result node and creates two relationships from subject to result and from result to requirement.
The graph may look something like this now:
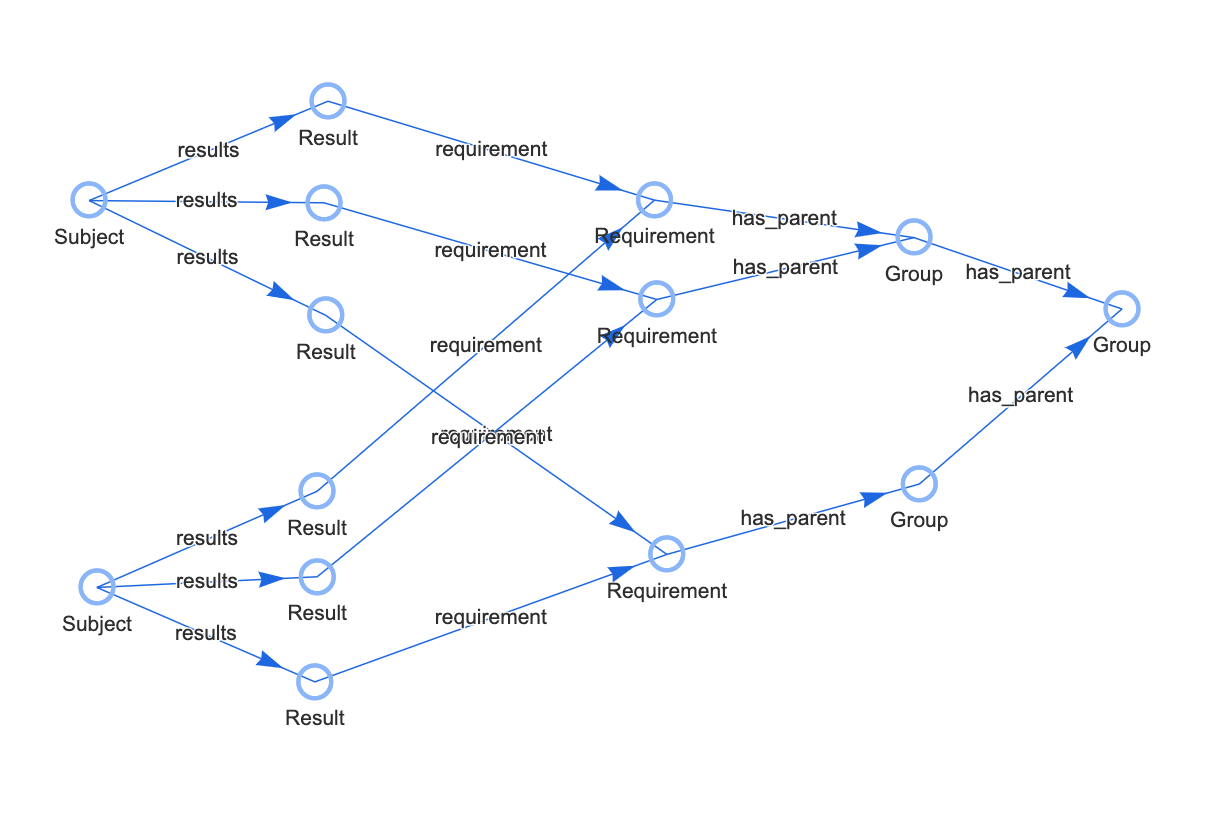
Graph visualization using the Quine web UI.
Streaming data out of Quine
My goal was to have the rollup computations performed in Quine and emitted as streaming events when any of the result nodes change. I record those in our relational database for the webservice’s API to retrieve with simple queries. To emit the data, we create a Standing Query. This query identifies changes that match and can trigger additional queries to fetch data and emit to one of several outputs, such as a log file, or Kafka topic.
The first part of the Standing Query includes the pattern of data that triggers further behavior. Normally, they are only triggered when added items join the set of results represented by the query. The includedCancellations option set to true requests that the Standing Query be triggered for nodes that stop matching the criteria as well. This works to detect any substantive change in my data set, as I have a status field that is either PASS or FAIL
{
"includeCancellations": true,
"pattern": {
"query": "
MATCH (s :Subject)-[:results]->(res :Result)-[:requirements]->(req :Requirement)-[:has_parent]->(g :Group)
WHERE res.status = 'PASS'
RETURN DISTINCT id(res) as id
",
"type": "Cypher"
},
…
}
Next, we want to do something in response to finding these results that change their status. Namely, I want to aggregate the total and passing counts for each level in the graph of groups for each subject that has results. So, we will add to the standing query an output:
"outputs": {
"createGroupResult": {
"type": "CypherQuery",
"query": "
MATCH (subject :Subject)-[:results]->(res :Result)-[:requirements]->(:Requirement)-[:has_parent*]->(group :Group)
WHERE id(v) = $that.data.id
MATCH (subject)-[:results]->(allres :Result)-[:requirements]->(:Requirement)-[:has_parent*]->(group :Group)
RETURN id(subject) as subject_id, id(group) as group_id, sum(CASE allres.status WHEN 'PASS' THEN 1 ELSE 0 END) AS pass, count(av) as total
", …
That creates another CypherQuery that will consume the result IDs that changed, and computes the rollups needed. It first matches on the subject related through that result, and with relationship expression -[:has_parent*]-> it matches all the groups in the parent hierarchy. Then it performs another match constrained to that subject and each of those groups, where it finds allres (all the results in between) and uses the aggregation functions sum and count to produce the pass and total values.
That little ‘*’ asterisk replaces the need we had for recursive query functions in my RDMS that are complex, and difficult to work with in SQL. In a graph walking an n length chain of relationships is a natural fit. With an RDBMS it is often a requirement to predict this sort of query requirement and denormalize the data insertion to accommodate efficient retrieval. Or it requires fairly complex queries. When solving this with an RDBMS you are creating a bespoke, poor man’s graph data store, overtop models optimized for completely different purposes. However you do so without any of the tools inherent in Quine and the Cypher query language that allow working with the data efficiently.
For future queries, I wanted to record these aggregations back into the graph. So before chaining in an external output to the Kafka Stream, I add another CypherQuery to the chain:
"andThen": {
"type": "CypherQuery",
"query": "
MATCH (subject :Subject), (group :Group)
WHERE id(subject) = $that.data.subject_id AND id(group) = $that.data.group_id
MATCH (gr)
WHERE id(gr) = idFrom('group_result', id(subject), id(group))
CREATE (subject)-[:group_results]->(gr)-[:has_group]->(group)
SET gr = {pass: $that.data.pass, total: $that.data.total}, gr:GroupResult
RETURN subject.subject_id as subjectId, group.id as groupId, group.name as name, gr.pass as pass, gr.total as total
", …
This matches the group and subject from the previous output IDs, and then materializes a GroupResult that holds the pass and total values with relationships to that group and subject. Finally, it defines the return expression which will be a JSON object containing subjectId, groupId, name, pass, and total fields. We send them on to an external output by adding an andThen to the previous CypherQuery.
Note: for testing purposes, much like you can ingest from files, you can output to a file with a WriteToFile in the output chain: andThen:{type:WriteToFile, path: rollups.json}
A Win-Win Situation
My organization has chosen to use Kafka streaming to produce our event data flows, as well as to build our web services APIs over top traditional RDBMs data stores for skill set purposes. By emitting my rollup values and storing them into the RDBMs, I am effectively materializing the view required to optimize answering the data questions our API authors encounter.
Working with the graph provides a flexible approach over simulating a graph in an RDBMS with recursive queries. Ramp up on the Cypher query language was quick, as there are concise training materials in video form on various learning websites. Learning to ingest the data, compute the rollups and egress the data from Quine took me about the same amount of clock time as a team of people spent expressing the recursive queries and tuning them in the RDBMS. The biggest issue being that, as a rule, with an RDBMS you must optimize your data insertion model for your data retrieval needs. This can lead to substantial changes for little questions. With Quine’s graph model, it is much easier to make incremental changes to the event data models without rewriting the whole pipeline.
Additionally, by feeding the rollups back into the Quine graph, they are available as inputs to further standing queries. It now becomes easy to create further events when the rollups change, such as raising a red flag if one of the subjects scores too low for one of the top tier groups.
Courses I used to ramp up on the Cypher query language:
- NoSQL: Neo4j and Cypher (Part: 1-Beginners) https://www.udemy.com/course/neo4j_beginners1/,
- NoSQL: Neo4j and Cypher (Part: 2-Intermediate) https://www.udemy.com/course/neo4j_intermediate/





